概述
传统监督学习通过对大量有标记的训练样例进行学习以建立模型用于预测未知样例的标记。在实际应用中,往往可以容易地收集到大量未标记的样本,而对这些数据赋予标记则往往需要耗费大量的人力物力。例如在进行计算机辅助医学影像分析时, 可以从医院获得大量医学影像, 但如果希望医学专家把影像中的病灶全都标识出来则是不现实的。
在这些获取标记数据困难的领域中,如果只使用少量有标记的数据,那么所训练出的学习系统可能很难具有强泛化能力,另外大量未标记数据未得到使用是对数据资源的极大浪费。因此,人们尝试将大量的无类标签的样例加入到有限的有类标签的样本中一起训练来进行学习,期望能对学习性能起到改进的作用,由此产生了半监督学习。
周志华. 基于分歧的半监督学习[J]. 自动化学报, 2013, 39(11): 1871-1878.
刘建伟, 刘媛, 罗雄麟. 半监督学习方法[J]. 计算机学报, 2015, 38(8): 1592-1617.
依赖的假设
未标记数据并不总是有助于半监督学习,只有在模型假设正确时,未标记数据才能发挥作用。两个常见的假设是聚类假设(Cluster Assumption)和流形假设(Manifold Assumption)。聚类假设指假设数据存在簇结构,同一个样本的簇属于同一个类别。在这种假设下,未标记数据发挥的作用可见图1,聚类假设通常用于分类任务。这个假设的等价定义为低密度分离假设,即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例分到决策边界两侧。
流形假设即假设数据分布在一个流形结构上,邻近的样本具有相似的输出值。流形(manifold)是几何中的一个概念,它是高维空间中的几何结构,即空间中的点构成的集合。图2为三维空间的流形。流形假设的观点认为,我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示。“邻近”程度常用“相似”程度来刻画,但流形假设对输出值没有限制,因此比聚类假设的使用范围更广。
有综述还列出了平滑假设(Smoothness Assumption),即假设位于稠密数据区域的两个距离很近的样例的类标签相似,也就是说,当两个样例被稠密数据区域中的边连接时,它们在很大的概率下有相同的类标签;相反地,当两个样例被稀疏数据区域分开时,它们的类标签趋于不同。这三个假设本质上都是基于“相似的样本拥有相似的输出”这个基本假设。许多实验研究表明,当半监督学习不满足这些假设或者模型假设不正确时,未标记数据不仅不能对学习性能起到改进作用,反而会恶化学习性能,导致性能下降。但也有实验表明,在一些特殊的情况下,即使模型假设正确,未标记数据也有可能损害学习性能。
Zhou Z H. A brief introduction to weakly supervised learning[J]. National Science Review, 2017, 5(1): 44-53.
刘建伟, 刘媛, 罗雄麟. 半监督学习方法[J]. 计算机学报, 2015, 38(8): 1592-1617.
类别
半监督学习目前大致有四种主流范型:生成式方法、基于分歧的方法、低密度分离法和基于图的方法。
生成式方法
生成式方法是直接基于生成式模型的方法,此类方法假设所有数据都是由同一个“潜在”的模型生成的。假设模型$p(x,y)=p(y)p(x|y)$,其中$p(x|y)$是可识别的混合模型分布,例如高斯混合模型。使用大量未标记的数据,可以识别混合模型的分量(component)。此时未标记的数据的标签值可以看做是模型参数的缺失值。理想情况下,每个分量只需一个有标签的示例就能完全确定混合模型分布。
Zhu X J. Semi-supervised learning literature survey[R]. University of Wisconsin-Madison Department of Computer Sciences, 2005.
Nigam等人提出使用基于期望最大化(EM)和朴素贝叶斯分类器的组合来学习标记和未标记文档。在文本分类领域,未标记数据提供了关于单词的联合概率分布的信息,这种相关性是提高分类效果的有用信息来源。算法首先训练仅具有可用标记文档的分类器,并使用分类器通过计算缺失类标签的期望来为每个未标记文档分配概率加权类标签,然后用新的数据训练新的分类器,并迭代收敛。EM算法负责找到使得数据集(有标记和未标记)似然局部最大化的分类器参数。当数据符合模型的生成假设时,这种基本的EM算法很有效。
Nigam K, McCallum A K, Thrun S, et al. Text classification from labeled and unlabeled documents using EM[J]. Machine learning, 2000, 39(2-3): 103-134.
基于分歧的方法
基于分歧的方法生成多种学习器,让它们来合作利用未标记数据,学习器之间的分歧是保证学习过程继续的关键。基于分歧的半监督学习的研究始于Blum和Mitchell关于协同训练(Co-training) 的工作。该类技术较少受到模型假设、损失函数非凸性和数据规模问题的影响,学习方法简单有效、理论基础相对坚实、适用范围较为广泛。
论文提出利用协同训练方法利用未标记数据和标记数据进行网页分类。在网页分类问题中,页面可以用两种不同的信息描述,一种是网页中的文字,另一种是指向这个网页的超链接的提示文字。两种信息可以称为两个“视图”(views)。协同训练法要求数据具有两个充分冗余且满足条件独立性的视图, “充分 (Sufficient)” 是指每个视图都包含足够产生最优学习器的信息, 此时对其中任一视图来说, 另一个视图则是 “冗余 (Redundant)” 的。实验使用朴素贝叶斯算法,在已标记数据中训练基于页面和基于超链接的分类器,然后用两个分类器分别预测未标记数据,再把这些数据分别加入对方分类器的数据集中,这个 “互相学习、共同进步” 的过程不断迭代进行下去, 直到两个分类器都不再发生变化, 或达到预先设定的学习轮数为止.。大体的流程如下图所示。
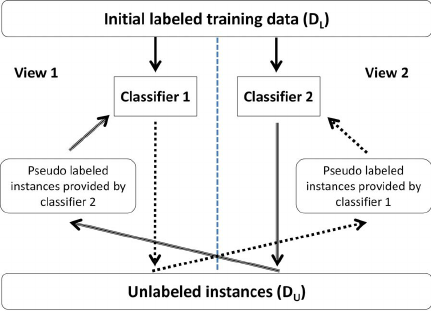
Blum A, Mitchell T. Combining labeled and unlabeled data with co-training[C]//Proceedings of the eleventh annual conference on Computational learning theory. ACM, 1998: 92-100.
标准的协同训练方法需要两个充足且冗余的视图,然而这种要求在现实场景中很难满足要求。为了确定分类器预测时的偏差,必须明确测定每个分类器的预测的置信度,有时这样的测量过程非常耗时。Tri-training(三训练或三体训练法)从单视图训练集中产生三个分类器, 然后利用这三个分类器以 “少数服从多数” 的形式来产生伪标记样本。具体来说,使用自采样(bootstrap sampling)方法从原始有标记数据集中获得三个数据集。每个训练集产生一个分类器,如果有两个分类器对标签预测达成一致,则标记此样例加入第三个分类器数据集。该方法避免了对标记置信度的显式估计。最终训练完成后, 三个分类器通过投票机制作为一个分类器集成进行使用。值得指出的是,最初的三个分类器必须强于弱学习器(所谓“弱学习器”,就是指性能比起随机猜测高一点的学习器),并且具有较大的分歧(即差异)。由于三训练不依赖于不同的视图,因此其适用范围更广。
Zhou Z H, Li M. Tri-training: Exploiting unlabeled data using three classifiers[J]. IEEE Transactions on Knowledge & Data Engineering, 2005 (11): 1529-1541.
低密度分离法
低密度分离法或者称为判别式方法,指利用最大间隔算法同时训练有类标签的样本和无类标签的样例学习决策边界,使其通过低密度数据区域,并且使学习得到的分类超平面到最近的样例的距离间隔最大。低密度分离法包括半监督支持向量机、熵正则化等。
半监督支持向量机中最著名的是TSVM(Transductive support vector machine,直推式支持向量机)。TSVM也是针对二分类问题的学习方法。但与标准SVM的不同,TSVM使用了未标记的数据。目标是找到未标记数据的标记,以便决策边界在原始标记数据和(现在标记的)未标记数据上有最大的距离间隔。直观地来说,未标记数据负责引导决策边界远离密集区域。下图展示了使用未标记数据的TSVM和仅使用已标记数据的SVM划分的决策边界的区别。
TSVM 是在文本分类的背景下提出的,更强调直推式的概念。通常的支持向量机(SVM)都是归纳式的,它们试图为一个分类任务归纳出一个一般的决策函数,以便对新来的样本能正确分类。而直推式支持向量机只考虑一个特定的测试数据集,试图最小化这个测试集上的错分率,而不考虑一般的情况。
Joachims T. Transductive inference for text classification using support vector machines[C]//Icml. 1999, 99: 200-209.
S3VM(Semi-supervised support vector machine)与TSVM在同一年提出。算法 主要的思想和求解的优化问题类似。半监督支持向量机(S3VM)刚提出时也是做为直推式的,主要用来对未标记的样本的类别进行直接估计,但它还在整个输入空间中划出了一个决策边界,所以也可以提供对新来的样本的分类。
Bennett K P, Demiriz A. Semi-supervised support vector machines[C]//Advances in Neural Information processing systems. 1999: 368-374.
基于图的方法
基于图的方法的实质是标签传播(Label Propagation),基于流形假设,根据样例之间的几何结构构造图,用图的结点表示样例,利用图上的邻接关系将类标签从有类标签的样本向无类标签的样例传播。模型的性能取决于图是如何构建的。下图为标签传播算法的实例,初始时仅有少量有标记的样例,经过多次迭代后,有标记的样例逐渐传播,两个半圆形数据已经被分为了两类。