前几天学了Python爬虫的一些基础,就想拿个网站来练练手。我想到了最近一直在用的GiWiFi登录网站,所以就用此网站做模拟登陆。
我使用Chrome的开发者工具来抓取网页链接信息。随便点击一个网站,就会跳转到GiWiFi的登录界面,如图:
首次跳转的网页是http://10.12.0.9:8062/redirect?oriUrl=http://www.baidu.com?ua=Mozilla

如图所示,再把抓取的Request Headers记录下来,使用requests模块的get方法
url_redirect = 'http://10.12.0.9:8062/redirect?oriUrl=http://www.baidu.com?ua=Mozilla'
headers_get = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.6,en-US;q=0.4,en;q=0.2',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36',
}
direct_web = requests.get(url_redirect, headers=headers_get)
再次跳转http://login.gwifi.com.cn/cmps/admin.php/api/login/?gw_address=10.12.0.9&gw_port=8060&gw_id=GWIFI-qingdaoshankeda09&ip=10.15.63.220&mac=B8:EE:65:0A:2F:D5&url=http%3A//www.baidu.com%3Fua%3DMozilla&apmac=00:90:fb:57:3f:56&ssid=。第一次网页返回的URl即是第二个网页的URL,且此步出现了Cookie。
login_web = requests.get(direct_web.url, headers=headers_get)
填写用户名和密码后点击登录,发现捕获到的首个URl为http://login.gwifi.com.cn/cmps/admin.php/api/loginaction?round=228,请求方法为POST,可推测这就是发送表单的地方。捕获到的Headers里有Form Data,里面发现了之前填写的用户名和密码。
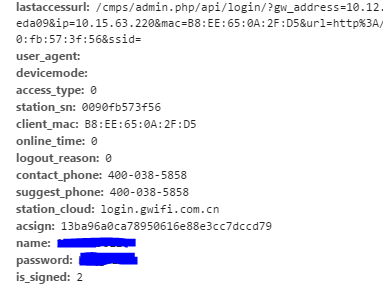
后来我发现里面的一些数据并非固定,有些ip mac等数据是随计算机和网络所处环境而变化的,所以需要从之前的网页中提取内容,第二次跳转的URL中含有动态信息,使用urlparse配合urllib.parse.parse_qs将之提取出来:
p = urlparse(login_web.url)
url_info = urllib.parse.parse_qs(p[4])
ip = url_info['ip'][0]
mac = url_info['mac'][0]
apmac = url_info['apmac'][0]
代码模拟POST如下:
headers_post = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.6,en-US;q=0.4,en;q=0.2',
'Connection': 'keep-alive',
'Content - Length': '807',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'http://login.gwifi.com.cn',
'Referer': login_web.url,
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36',
}
data = {
'PHPSESSID': '',
'access_type': '0',
'acsign': '4214a9d5a003f41db893751e9eeb7934',
'apinfo': '',
'btype': 'pc',
'client_mac': 'B8:EE:65:0A:2F:D5',
'contact_phone': '400-038-5858',
'devicemode': '',
'gw_address': '10.12.0.9',
'gw_id': 'GWIFI-qingdaoshankeda09',
'gw_port': '8060',
'ip': ip,
'is_signed': '2',
'lastaccessurl': login_web.url,
'logout_reason': '8',
'mac': 'B8:EE:65:0A:2F:D5',
'name': 'xxxxxxxxxxx',
'olduser': '0',
'online_time': '36',
'page_time': '1491994922',
'password': '******',
'station_cloud': 'login.gwifi.com.cn',
'station_sn': '0090fb573f56',
'suggest_phone': '400-038-5858',
'url': 'http://www.baidu.com?ua=Mozilla',
'user_agent': ''
}
print('Authorizing…')
url_tar = 'http://login.gwifi.com.cn/cmps/admin.php/api/loginaction'
requests.post(url_tar, data=data, headers=headers_post, cookies=login_web.cookies)
下一个访问的网页是http://10.12.0.9:8060/wifidog/auth?token=c6a4f3460f89c02b6cf3a514f4a4523ffbdc299a&info=MiTfci4wNgTQyNTgyMjQsLDIwMTcwNDE0MTA1NjM1
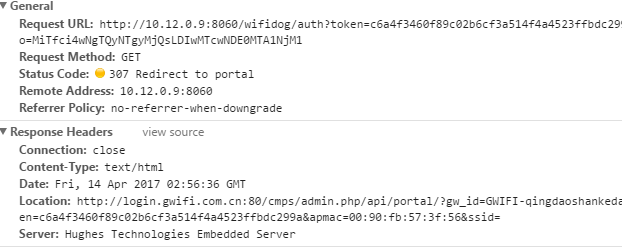
我看到里面有"wifidog"字样,于是就上网查了一下,WiFiDog是一套用来做无线WiFi热点认证管理的开源工具。它会在用户提交登录数据时进行认证,并生成一个token。这个token我后来发现是随机的,而且不可逆。再次跳转的网页是http://login.gwifi.com.cn/cmps/admin.php/api/portal/?gw_id=GWIFI-qingdaoshankeda09&token=c6a4f3460f89c02b6cf3a514f4a4523ffbdc299a&apmac=00:90:fb:57:3f:56&ssid=
url_token = 'http://10.12.0.9:8060/wifidog/auth?token=7ba9a1553b53f049e7a983750e887b0654c491b5&info=MiTfci4wNgTQyNTgyMjQsLDIwMTcwNDEyMTkwMjE4'
url_final = 'http://login.gwifi.com.cn/cmps/admin.php/api/portal/?gw_id=GWIFI-qingdaoshankeda09&token=7ba9a1553b53f049e7a983750e887b0654c491b5&apmac=00:90:fb:57:3f:56&ssid='
requests.get(url_token, headers=headers_get)
requests.get(url_final, headers=headers_get)
最后跳转至百度首页,表示登录成功。因为此网站使用一次性的token进行验证,且token无法获取。所以只能在登录后的一段时间内才可模拟成功。
Python 3 爬虫基础资料: https://www.gitbook.com/book/germey/python3webspider
类似的模拟登录实例: http://blog.csdn.net/abitch/article/details/51939879
完整代码参见,部分数据可能与本文不同: GiWiFi_Login.py