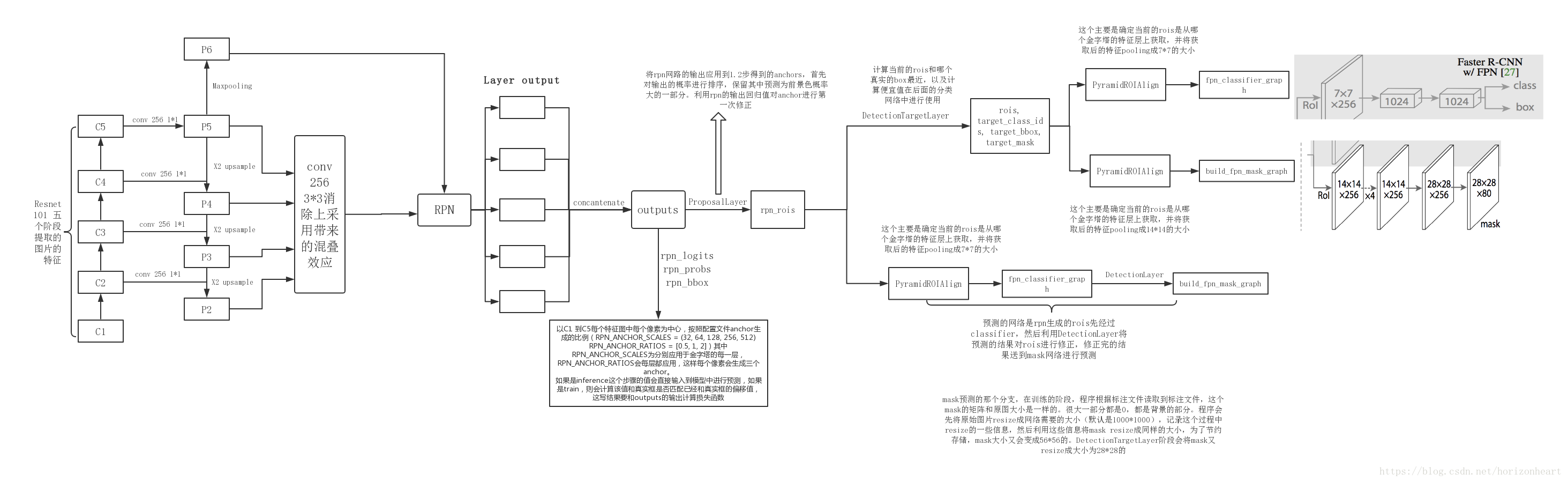
骨干架构(FPN)
特征金字塔网络是一种多维度特征表达,主要解决物体检测中的多尺度问题,可大幅提升小物体检测的性能。网络由浅至深,低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。特征图金字塔分成三个部分,一个自底向上的路径(左边),一个自顶向下的路径(右边)和横向连接部分。
自底向上路径
卷积网络的前馈计算,特征图经过卷积核计算后大小会有所改变,也有一些层不会改变,称为“相同网络阶段”。每个相同网络阶段定义一个金字塔级别,选择最后一层的输出作为特征图。对于ResNet,论文使用每个阶段的最后一个残差结构的特征激活输出,分别表示为C2、C3、C4、C5,共四个特征图,其中C5为最后一层也就是金字塔最顶层的输出。
自顶向下路径和横向连接
Resnet最顶层输出C5,通过一个1 * 1的卷积层降低通道维度,即得到本路径最上层的P5。P4为上采样后的P5与1 * 1卷积后的C4进行横向连接而来,连接方式是做像素间加法。向下的P3和P2也用相同方法得出。这些自顶向下得到的特征图最后会做一次3 * 3的卷积,作用是消除上采样带来的混叠效应,最终得到4个融合不同层级的特征图。在RPN的嵌入中,另有第五个特征图P6,由P5经最大池化层后得来。
RPN
RPN网络部分输出三组数据:Anchors类别的原始分数(做Softmax之前的值)、Anchors类别的概率和Anchor偏移值。
Region Proposal
依据上部分的Anchor偏移值(dy, dx, log(dh), log(dw)),对原始的Anchor(y1, x1, y2, x2)坐标进行调整,最终输出修正后的坐标。再经过非最大值抑制的筛选,得到1000个感兴趣区域(ROI)。
RCNN部分
输入特征图和ROI数据,首先进行ROI Align,再对ROI做类别预测和边框回归,根据概率进一步筛选,最终输出检测到的ROI(y1, x1, y2, x2, class_id, score)。
ROI Pooling和ROI Align
ROI Align是于Mask-RCNN中提出的区域特征聚集方式,用于代替ROI Pooling。在之前的目标检测框架中(如Fast-RCNN、Faster-RCNN等),ROI Pooling的作用将尺寸不同的ROI池化为固定尺寸,以便后续的分类和边界框回归操作。
由于ROI的位置通常由模型回归得到,一般来说是浮点数,而池化后的ROI要求尺寸固定。所以ROI Pooling存在两次量化过程:
- 将ROI边界坐标量化为整数坐标值。
- 将量化后的边界区域平均分割成 k x k 个单元,对每一个单元的边界进行量化。
比如,665 * 665的矩形框经主干网络后的缩放步长为32,框的大小变为665/32=20.78,此时ROI Pooling将其量化为20。池化层的输出大小为7*7,等分后的子区域大小为20/7=2.86,此时将子区域大小量化为2。经过两次量化,此时的ROI位置已经和开始回归出来的位置有一定的偏差,这个偏差会影响检测或分割的准确度,尤其是对于小目标的检测。ROI Align取消了量化操作,使用双线性插值的方法,获得坐标为浮点数的像素点上的图像数值。
虚线部分表示feature map,实线表示ROI,这里将ROI切分成2x2的单元格。如果采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示,核心思想是在两个方向分别进行一次线性插值),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行最大池化,就可以得到最终的ROIAlign的结果。
在ROI Align中,不同大小的ROI,使用不同特征层映射作为本层的输入,面积大的ROI使用靠上的金字塔层,面积小的ROI使用靠下的金字塔层,然后送入同一个分类和回归网络得到最终结果。
Mask分支(FCN)
Mask预测分支使用小型的全卷积网络(FCN),对每个ROI,应用一个全卷积网络做分割,求出目标所在区域。实际操作中,对ROI区域调用ROI Align生成固定大小的特征图,再经过4个卷积操作后,生成14 * 14大小的特征图,然后经过上采样生成 28 * 28 大小的特征图(对目标形状的描述)。假设一共有K个类别,则输出维度是 K * 28 * 28,也就是说对于 28 * 28 中的每个点,都会输出K个二值Mask(每个类别使用sigmoid输出)
将原图各分类的Mask区域映射成 28 * 28 大小的mask特征图,最后计算预测区域和真实区域的平均二值交叉损失熵。需要注意的是,计算损失的时候,并不是每个类别的sigmoid输出都计算二值交叉熵损失,而是该像素属于哪个类,哪个类的sigmoid输出才要计算损失。这与FCN原本的方法不同,FCN是对每个像素进行多类别softmax分类,然后计算交叉熵损失,很明显,这种做法是会造成类间竞争的,而每个类别使用sigmoid输出并计算二值损失,可以避免类间竞争。
下图为Mask R-CNN整个流程的图示,请放大后查看:
参考资料: