概念
在现实生活中,我们遇到的数据大多数都是非线性的,因此不能用线性回归的方法来进行数据拟合,这就需要用到逻辑回归。逻辑回归虽然名字里带“回归”,但是实际上是一种分类方法,用于两分类问题。基本过程如下:
- 找一个合适的预测函数,而函数的输出必须只有两个值,所以这里利用逻辑函数(或称Sigmoid函数),形式如下,图像是一个取值为0到1的S型曲线。 $$ g(z) = \frac{1}{1+e^{-z}} $$
- 构造损失函数。这里的损失函数和$ J(\theta) $函数都是通过最大似然估计推导得到的。
- 找到$ J(\theta) $函数的最小值。寻找函数最小值有许多方法,如梯度下降法。
具体公式及推导可参考:https://blog.csdn.net/ligang_csdn/article/details/53838743
TensorFlow实现
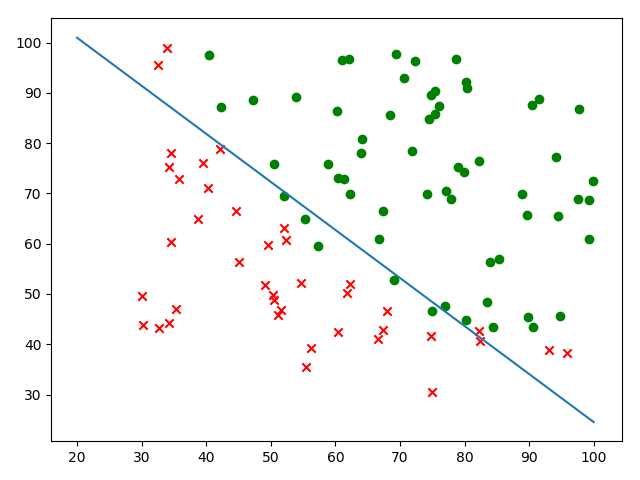
数据集使用Andrew Ng机器学习课程中的ex2data1.txt,根据学生的两次考试成绩判断该学生是否会被录取。数据有3组,前2组为两次考试成绩,第3组为是否被录取,1代表被录取,0则没有被录取。
首先需要将数据读入并分离。
df = pd.read_csv("ex2data1.txt", header=None)
train_data = df.values
train_X = train_data[:, :-1] # 前两组
train_y = train_data[:, -1:] # 第三组
feature_num = len(train_X[0]) # 特征数,本例为2
sample_num = len(train_X) # 样例数,本例为100
然后定义数据集和训练目标,其中W为权值矩阵,b为偏置量。
# 定义数据集
X = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# 训练
W = tf.Variable(tf.zeros([feature_num, 1]))
b = tf.Variable([-0.9]) # -0.9为自定义
接下来定义预测函数和损失函数,并进行优化。
db = tf.matmul(X, tf.reshape(W, [-1, 1])) + b
hyp = tf.sigmoid(db) # 预测函数
cost0 = y * tf.log(hyp)
cost1 = (1 - y) * tf.log(1 - hyp)
cost = (cost0 + cost1) / -sample_num # J(θ)函数
loss = tf.reduce_sum(cost) # 损失函数
train = tf.train.GradientDescentOptimizer(0.001).minimize(loss) # 使用梯度下降法,学习率0.001
下一步开始训练。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(1000000): # 进行一百万次训练
sess.run(train, {X: train_X, y: train_y})
if step % 100 == 0:
print(step, sess.run(W).flatten(), sess.run(b).flatten())
最后进行可视化,最终得出的图像如下: