全卷积网络(FCN)对图像进行像素级的分类,用于语义分割。FCN与CNN的主要区别在于,FCN将传统CNN中的全连接层转化为1 * 1的卷积层。与传统的CNN网络不同,FCN可以接受任意尺寸的输入图像,然后采用反卷积进行上采样,使之恢复到与输入图像相同的尺寸,从而可以预测每个像素。
例如经过5次卷积和池化后,图像的分辨率依次缩小了2,4,8,16,32倍。最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。这个上采样是通过反卷积(deconvolution)实现的。
对第5层的输出反卷积的到原图大小,最终的分割结果仍然不够精确,所以考虑加入更多前层的细节,也就是将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,与最后的输出做一个融合,实际操作为相加,结果表现更加精细。这种结构称为跳级结构。
FCN的整体结构如下图所示:
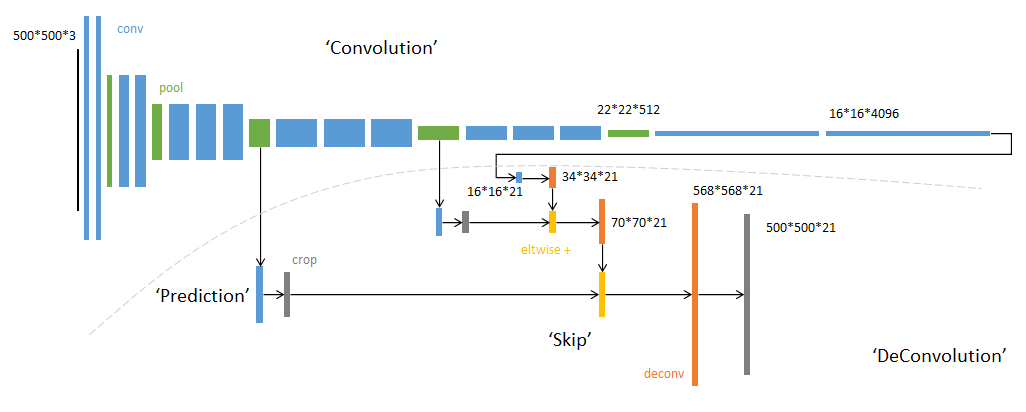
- 蓝色:卷积层
- 绿色:最大池化层
- 黄色: 求和运算,将三个不同深度的预测结果逐数据相加进行融合:较浅的结果更为精细,较深的结果更为鲁棒
- 灰色: 裁剪, 融合之前使用裁剪层统一两者大小, 最后裁剪成和输入尺寸相同的输出
- 对于不同尺寸的输入图像,各层数据的尺寸相应变化,深度不变
- 虚线内为反卷积层的运算
在Mask RCNN中的应用
在Mask RCNN添加的Mask分支中,每个ROI应用一个小型的FCN网络,虽然FCN用于语义分割,但是每个ROI只有一类,这样总体上相当于实现了实例分割。不过Mask分支和原始的FCN有所不同,Mask分支中每个像素点的预测和类别判断是分开的。Mask分支的预测是一个二值,它的类别判断由前面的分类预测完成,而原始的FCN输出是一个Softmax输出,判断每个像素点属于哪个类别。